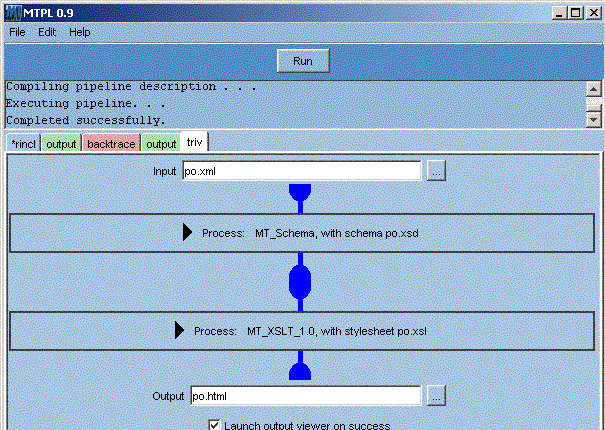
Figure 3: Graphical UI Example: Pipeline with input and output specified
A screenshot of MT Pipeline Lite displaying the concise view of a two-step pipeline
Keywords: data interchange, XML processing, XML pipelines
Biography
Henry S. Thompson is Managing Director of Markup Technology Ltd. He is also Reader in Artificial Intelligence and Cognitive Science in the Division of Informatics at the University of Edinburgh, based in the Language Technology Group of the Human Communication Research Centre. He received his Ph.D. in Linguistics from the University of California at Berkeley in 1980. His university education was divided between Linguistics and Computer Science, in which he holds an M.Sc. His research interests have ranged widely, including natural language parsing, speech recognition, machine translation evaluation, modelling human lexical access mechanisms, the fine structure of human-human dialogue, language resource creation and architectures for linguistic annotation. His current research is focussed on articulating and extending the architectures of XML. Markup Technology is focussed on delivering the power of XML pipelines for application development. Henry was a member of the SGML Working Group of the World Wide Web Consortium which designed XML, is the author of the XED, the first free XML instance editor and co-author of the LT XML toolkit and is currently a member of the XSL and XML Schema Working Groups of the W3C. He currently is a member of the W3C Team, and is lead editor of the Structures part of the XML Schema W3C Recommendation, for which he co-wrote the first publicly available implementation, XSV. He has presented many papers and tutorials on SGML, DSSSL, XML, XSL and XML Schemas in both industrial and public settings over the last five years.
Divide-and-conquer is as useful an approach to XML processing tasks as it is to any other software engineering problem. There are existing approaches to supporting decomposition of XML processing, both ad hoc and purpose-designed, which attempt to address this, but they suffer from conceptual and practical problems. The work reported here focusses on addressing these problem as manifested in the Sun XML Pipeline W3C Note.
There is renewed interest in the design of a general-purpose approach to local XML processing which can function as the fine-grained counterpart to the coarse-grained decomposition which various approaches to choreography for Web Services have advocated. The Sun XML Pipeline Note can be a good starting point for satisfying this requirement, provided it is re-interpreted in the right way. This paper proposes a re-interpretation of the pipeline description document type of the Note, allowing it to be understood as simply specifying a configuration of operations on XML-encoded information, and discuss the benefits which follow from this move.
Introduction
The Sun XML Pipeline Note
Requirements for XML processing
Re-Interpretation of the Sun XML Pipeline Note
Examples with a Graphical User Interface
Conclusions
Acknowledgements
Bibliography
Divide-and-conquer is as useful an approach to XML processing tasks as it is to any other software engineering problem. So the lack of a coherent XML processing model to support decomposition of complex XML processing tasks represents a serious bottleneck in enterprise use of XML in general and Web Services in particular. Today, most XML processing implementations are ad hoc, based on custom programming to link together XML operations. Early adopters of XML have already found this approach to result in poor runtime performance along with an unacceptably high cost of program maintenance. Reliance on scripting or other forms of custom programming is far from the enterprise-class solution that will increase adoption of XML for mission-critical tasks such as building Web Services. XML processing demands the same standards that have evolved for all other classes of enterprise software.
Existing approaches to supporting decomposition of XML processing, whether ad hoc (e.g. UNIX shell scripts, SAX Filter chains, JMS-connected beans) or purpose-designed (e.g. McGrath/Propylon's XPipe [XPipe] , Sun's XML Pipeline [SunPipe] ), all attempt to address this, but suffer from built-in inefficiencies. The work reported here focusses on addressing this problem as it manifests itself in the Sun XML Pipeline W3C Note.
There is renewed interest in the general issue of a general-purpose approach to local XML processing which can function as the fine-grained counterpart to the coarse-grained decomposition which various approaches to choreography for Web Services have advocated. The Sun XML Pipeline Note can be a good starting point for satisfying this requirement, provided it is re-interpreted in the right way.
As written, the XML Pipeline Note is dependency-driven, in the mode of
make and ant. This means that all inputs and outputs at every
step in a pipeline must be actual files or otherwise possessed of reliable timestamps, so that their status as
up-to-date or not can be determined. Not only does this preclude message-based
input and output and militate against non-local URIs, it also means that
multi-step pipelines require at least serialisation and probably parsing between each
step.
This paper proposes a re-interpretation of the pipeline description document type of the Note, allowing it to be understood as simply specifying a configuration of operations on XML-encoded information. This re-interpretation allows intermediate results to be passed between components without serialisation, and facilitates embedding pipelines e.g. in app-servers where they can then operate on message-derived input to produce message-delivered output.
It is hard to over-emphasise the value of making decomposition easily available: in a recent development effort, the ability to trivially construct a pipeline of eight successive XSLT steps mixed with several other processes allowed me to build a complex application in a day, where building a single stylesheet to do the whole thing, although possible, would have taken much more work, and produced a much less robust outcome.
The fundamental idea behind the proposal presented in
[SunPipe]
is that XML processing is driven by a declarative statement of dependencies between XML-encoded resources, together with explicit instructions for how to construct a given resources from the resources it depends on. This approach is similar to that of the Java utility ant, which in turn is derived from the UN*X utility make.
Basically an XML processing pipeline, as defined in [SunPipe] , consists of a set of steps with labelled inputs and outputs. The labels, which are URIs, serve two purposes: connecting steps together, and determining dependencies which in turn determine what processing actually takes place. That is, when a pipeline is 'run', its non-intermediate outputs are identified (outputs which are not also inputs). If any of these are not up-to-date, that is, newer than any of their inputs, they must be re-constructed. The up-to-date check must then be done on the inputs required for this, and so on. The result is a backwards-then-forwards flow: backwards via the dependency chain(s), then forwards executing steps and producing (possibly intermediate) outputs.
Individual steps are specified by naming a process, one or more inputs, one or more outputs, and zero or more named parameters. The mapping between process names and actually processing is indirect, since this is likely to be implementation dependent. The indirection is there to minimize the cost of porting a pipeline to a new implementation environment. The example below illustrates this, as well as the use of labels to connect the steps, and other aspects of the design.
<pipeline xmlns="http://www.w3.org/2002/02/xml-pipeline"
xml:base="http://example.org/">
<param name="target" select="'result'"/>
<processdef name="xinclude.p" definition="org.example.xml.Xinclude"/>
<processdef name="validate.p" definition="org.example.xml.XmlSchema"/>
<processdef name="transform.p" definition="org.example.xml.XSLT"/>
<process id="p3" type="transform.p">
<input name="stylesheet" label="mystyle.xsl"/>
<input name="document" label="valid"/>
<output name="result" label="result"/>
<param name="chunk">0</param>
</process>
<process id="p2" type="validate.p">
<input name="document" label="xresult"/>
<input name="schema" label="someschema.xsd"/>
<output name="result" label="valid"/>
<error name="invalid" label="#invalidDocument"/>
</process>
<process id="p1" type="xinclude.p">
<input name="document" label="myfile.xml"/>
<output name="result" label="xresult"/>
</process>
<document name="invalidDocument">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Failure!</title>
</head>
<body>
<h1>Your job failed because the document is invalid.</h1>
</body>
</html>
</document>
</pipeline>
|
Figure 1: Example Sun Pipeline
This is the first example from [SunPipe]
Needless to say, this brief summary gives only a partial picture of the proposal, but it is sufficient for our purposes in this paper.
There are several requirements for an effectively deployable approach to specifying XML processing pipelines which the [SunPipe] proposal does not satisfy.
First, from the perspective of service-oriented
architectures and information integration, thinking of pipelines as recipes for
processing any XML document, not just a particular named resource, is
clearly fundamental. A web service, for instance as defined by a WSDL
definition, is essentially a mapping from XML to XML, and a pipeline is a way
of implementing such a mapping. As such we want to think of it more like a
UN*X shell script, mapping from (XML) input to (XML) output, rather than as a
UN*X Makefile.
Second, intermediate results are rarely of interest outside of debugging, and requiring them to be named and actually created as XML documents is at least an unnecessary implementation burden. At worst, when a pipeline is intended to run in an app-server, with the potential for many instances to be executing simultaneously, the notion of named intermediate results is seriously problematic.
In order to address the incompatibility between requirements and existing functionality identified in the previous section, we have designed a usage profile for and extended the semantics of the XML document type defined in [SunPipe] for specifying XML pipelines.
To address the first problem above, i.e. viewing pipeline definitions
as XML-in/XML-out function definitions, we simply introduce two distinguished
'URIs', namely $IN for the primary input and $OUT for
the primary output. Running a pipeline definition with such an input and/or
output specified will read XML from its standard input/write XML to its
standard output, respectively.
To address the second problem, i.e. avoiding named intermediaries, we interpret naked fragment identifiers as internal connections not requiring serialisation.
A trivial two-step pipeline exploiting both these features would look appear as in Figure 2 below:
<p:pipeline> <p:processdef name="validate" definition="MT_Schema"/> <p:processdef name="transform" definition="MT_XSLT_1.0"/> <p:process type="validate"> <p:input label="$IN"/> <p:input name="schema" label="po.xsd"/> <p:output label="#vres"/> </p:process> <p:process type="transform"> <p:input label="#vres"/> <p:input name="stylesheet" label="po.xsl"/> <p:output label="$OUT"/> </p:process> </p:pipeline> |
Figure 2: New pipeline example
An example pipeline definition mapping from standard input to standard output with no named intermediary
Another way to think about the re-interpretation, using the UN*X
make analogy, is to think of always running with the switches
which treat all dependencies as infinitely new.
We have implemented a cross-platform graphical tool which supports the re-interpretation described here. Here's a screen-shot of the tool working with the simple example shown above in Figure 2:
Figure 3: Graphical UI Example: Pipeline with input and output specified
A screenshot of MT Pipeline Lite displaying the concise view of a two-step pipeline
The above display shows a complete pipeline ready to run -- expanding a step allows it to be modified, as shown in the following screenshot:
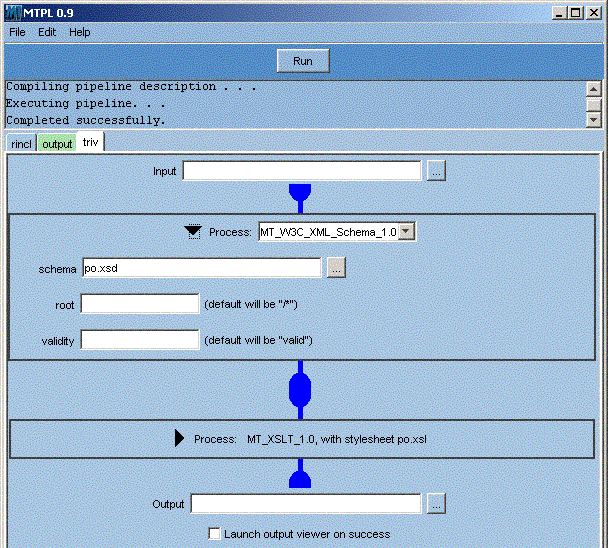
Figure 4: Graphical UI Example: Editable pipeline
A screenshot of MT Pipeline Lite displaying the editable view of a two-step pipeline
The above display shows how parameters and secondary inputs can be set. The inventory of these will change if the pull-down menu is used to change the processing step. The inventory of supported processing steps includes W3C XML Schema validation, XSLT (including type-aware patterns from XPath 2.0) and XInclude as well as an inventory of simple operations such as extracting, embedding, renaming and deleting, and an escape to arbitrary user-defined processes defined on serialised input and producing serialised output.
We believe that processing XML as XML can often be the best way to build XML applications. Making it easy to decompose XML processing tasks into steps without resulting inefficiency (for pipelines with large numbers of steps our application runs approximately 5 times faster than the equivalent chain of command-line invocations) is an important step towards changing our outlook, so that instead of writing Java or Python code being the first thing we do when we start a new XML application, it's either the last thing we do, or we don't do it at all.
Even within a context where the decision to work purely at the XML level has already been taken, easy-to-specify pipelines can make a big difference. I recently produced a Powerpoint to HTML transducer in about six hours' work, starting from Open Office 1.0's XML version and producing clean DocBook-like XML. I did this by successive improvement, one XSLT step at a time, and ended up with a seven-step pipeline, with most of the individual stylesheets having only four or five templates. I'm sure it could have been done in one stylesheet, but the multi-step approach was much easier to develop and much much easier to debug -- just look at the intermediate results (of course you can get intermediate results, you're just not forced to) and see which stylesheet is introducing (or failing to eliminate) the problem, and your job is already half-completed.
So pipelines are a very useful resource in the XML application developer's toolset, and they often can be specified purely declaratively at the level of sequences of standards-based XML processing steps. By making it easy to try this, we hope to change the way people think about XML processing altogether.
The work reported here was carried out at Markup Technology by the author, Mary Holstege, Alex Milowski and Richard Tobin.
A free-for-non-commercial-use implementation of a tool supporting the profile and semantics described here will be available shortly at http://www.markuptechnology.com/.
XHTML rendition created by gcapaper Web Publisher v2.1, © 2001-3 Schema Software Inc.